
















 Does copyright help keep works available, by giving the creators incentive to make sure it’s around to be purchased so they can get money? Or does it hinder keeping works available, since there’s only one source who can permit it and if they’re not interested nobody can compete with them? That’s the question law professor Paul J. Heald set out to test in a statistical study.
Does copyright help keep works available, by giving the creators incentive to make sure it’s around to be purchased so they can get money? Or does it hinder keeping works available, since there’s only one source who can permit it and if they’re not interested nobody can compete with them? That’s the question law professor Paul J. Heald set out to test in a statistical study.
Heald (and his research assistant) used random ISBNs to sample 7,000 books from Amazon and rank them by date of publication. Then he looked at how many books from each decade were available, to determine whether there were more of the ones that were still under copyright or more of the public domain titles. Guess what he found?
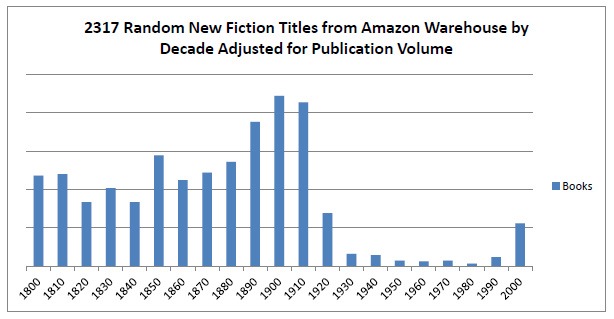 It turns out that considerably more of the titles were from the pre-1923 public-domain era than after. The results are even more dramatic in the chart at right, when he adjusts for the total number of books that were published in each era (given that considerably more books are published overall now that modern automation makes it simpler).
It turns out that considerably more of the titles were from the pre-1923 public-domain era than after. The results are even more dramatic in the chart at right, when he adjusts for the total number of books that were published in each era (given that considerably more books are published overall now that modern automation makes it simpler).
This hardly comes as a surprise to any advocate of the public domain and opponent of copyright term extension. It stands to reason that publishers don’t have a lot of incentive to keep older works in print, or go to the bother of scanning them into e-book form, if they don’t sell. And that’s leaving aside altogether the matter of orphaned works where the provenance is unclear. (This is one reason why it’s such a pity that the Google Books settlement didn’t go through. Imagine being able to look up any book Google had scanned but publishers or the author hadn’t bothered with, and buy it legally!)
Whereas, if a work is in the public domain, anyone can scan and upload it, and make it available for free or even for sale with appropriate value added. When it’s in copyright, you have to hope it’s worth the copyright owner’s time and trouble to sell it. If not, you’re out of luck. (And if it’s not one of the most popular works of its era, you’re not likely to be able to find it even on the pirate sites.)
The study also looks at the use of copyrighted vs. public domain songs in movies. It didn’t see as much use of public-domain works there, probably because use of even public domain works would cost money—paying musicians to record the work, for example. (Also, the study doesn’t go into this much, but compared to books, rights issues surrounding music are an unholy mess. See Nina Paley’s copyright struggle concerning the Annette Hanshaw music she used in Sita Sings the Blues for an example. So if you’re going to run into rights issues even with “public-domain” stuff, you might as well use new music.)
The last section looks at monetization of copyrighted works in YouTube videos. YouTube offers an interesting half-way step between not objecting to works and having them taken down, by allowing the copyright owner to insert a commercial at the start of the video and collect ad revenue from it. This means that copyright owners of works don’t have to do a thing to make it available themselves—someone else can do it for them, and they can step in afterward to earn royalties.
Heald looked at number-1 hit songs from the US, France, and Brazil from 1930 to 1960 to find out how many were available and what percentage of them had been monetized. The study found that most videos were uploaded by non-owners, but most of them—fully 73% of infringing US uploads, lower quantities in France and Brazil—had since been monetized by copyright owners. So, YouTube’s secondary liability acts as an antidote to the copyright-induced disappearance of older still-in-copyright works. You can find practically any song on YouTube. It may be paired with an anime music video, or even be an amateur performance (so to speak) instead of the hit recording version of the song, but it’s there.
Can you imagine what it would be like if there were something like that for e-books? Someplace pirates could upload their scanned e-texts of obscure works to, and the publisher or author who owned the rights could say, “That looks pretty good! Let’s let them sell that and let me get money from it.” They could give an agency-pricing percentage to the person who put it up there, for the work of scanning and proofing it to where it’s good enough to be sold professionally, and keep the rest of the money for themselves, since it is, after all, their book. The Google Books settlement would have done something like that, but it was probably a forlorn hope from the start.
Anyway, when you get right down to it, studies like these demonstrate that there’s no point for publishers to try to pretend they want copyright extension for noble keep-the-work-available reasons. They just want to hold onto their books for as long as they can—even if they don’t realize that it’s doing the book more harm than good. After all, they don’t know which one of those works is going to start selling like hotcakes sometime in the future—so they might as well keep them all, right? Even if they…don’t do anything with them ever again.
Now, to be fair, we are entering the age of the e-book, and some basic assumptions the study deals with could change as far as future content goes. The big holdup on making those 1923-through-2000 books available is that they’re all in print form, and scanning any of them into text would be a bit of an undertaking, requiring not just image capture but an actual editing process, that probably wouldn’t sell enough copies of most obscure old books to pay off what it cost to convert them (at least in any reasonable timeframe).
But modern books are submitted digitally from the get-go, as they’re published, so it’s not going to be any skin off a publisher’s nose to keep those available in at least electronic form for as long as they have the rights (and they haven’t reverted back to the author). Even when/if the rights have reverted back to the author, the author could self-publish the e-book themselves and let it stay available with very little effort involved—and thanks to the Long Tail, it would be like getting free money. So another version of this study done, say, fifty years from now might look very different, at least for the years 2010 and up.
All that being said, I don’t know if it’s likely or even possible that we’ll ever get any of these copyright extensions rolled back. The harm that copyright extension does is largely limited to esoteric books that no one wants to read anyway—hell, it’s hard enough getting anyone to want to read stuff that’s in the public domain as it is, or indeed, anything at all. It may be that we’re stuck with 95-year copyright terms forever because nobody really gives a damn. Still, studies like this are a clear indication of what we lose when we let publishers write our copyright laws for us, and it’s really just a shame.
(Found via Slashdot. See also, Paul’s take on the same study yesterday.)













Good point about the results of this study 50 years from now. This is what is relevant to authors and readers today. The friction of paper no longer exists. Publishers will try to extend copyright even further and nothing will go out of print because nothing is printed.
Still, sales are an incomplete metric where public domain options exist if what we’re interested in knowing is the availability of literature as contrasted to the availability of revenue.
Annotating the works of Shakespeare is a fine thing to do but if we only count the sales of those annotated versions we underestimate the interest in those works. Gutenberg downloads also count.
That’s why I prefer to pirate books.
Aren’t there provisions for a work to fall out of copyright if the publisher or author fail to publish (print or disseminate electronically) a work for a period of years? If not, that would be a sensible way to limit the negative impact of super-long copyrights. If you don’t offer a book for sale for 20 years, then it becomes public domain.
@Barry No, you are confusing it with a common publishing contract clause that allows the publishing rights to revert to the author if the publisher doesn’t ‘actively’ sell the product/keep it in print.
Copyright law , at least in the US, is now super-long, anything copyrighted here since 1978 remains so until the first of 70 years after authors death or 95 years from first publication or 120 years from first creation. Your proposal it well intentioned , but it may be difficult to determine if a book is for sale or not…i.e. the author may just sell them by hand at flea markets or other small events, etc.
I’d favor a return to something similar to the old system, 1st copyright 25 yrs, + 1 renewal of 25 more years. Thats it, simple/equitable to creators and the public.